拼好 AI:个人用户的轻量化 AI 模型聚合平台
前言
做这个项目的初衷,其实是为了把各处“白嫖”来的公益站资源做个整合。毕竟“嫖”来的接口稳定性难免波动,所以我需要一个能方便调用并支持故障转移的工具。为此,我尝试了一些开源的 API 网关,比如 New API 和 uni-api。
起初我选择了 New API,毕竟它是众多公益站的首选,功能确实强大且全面。但“成也萧何败也萧何”,对于我这种个人用户来说,它显得有些过于臃肿了。于是我开始寻找更轻量级的替代品,最终发现了 uni-api。
如果说 New API 是“大而全”,那 uni-api 绝对算得上“小而美”。它摒弃了复杂的功能,保留了核心需求。我使用了一段时间,体验总体不错。唯独在本地部署时遇到了前端 CORS 跨域问题(HTTPS 站点无法请求 HTTP 内容),导致官方提供的前端无法连接。正是这个前端问题,让我萌生了自己动手开发一个类似项目的念头。
拼好 AI
拼好 AI 是一个专为个人用户打造的轻量级 AI 模型聚合平台,其核心功能基于 任意门 项目构建。
核心特性
- 多源聚合:统一管理多个 AI 服务提供商,支持 OpenAI、Anthropic 和 Gemini 协议格式。
- 接口标准化:对外提供兼容 OpenAI 和 Anthropic 格式的标准化接口。
- 智能负载:支持自动负载均衡,有效分散请求压力。
- 高可用性:内置故障转移机制,自动切换至可用服务,保障服务连续性。
- 极简部署:支持 Docker 一键部署,配置门槛低。
- 数据存储:默认使用 SQLite,同时支持 MySQL 和 PostgreSQL。
- 可视化管理:内置直观的 Web 管理界面,操作便捷。
- 高级配置:支持模型名称映射、批量重命名、UA 透传/覆盖等灵活配置。
部署指南
Docker 部署
推荐使用 Docker 进行部署,这是最简单快捷的方式:
1 | # 拉取并运行最新版本(请自行设置 token) |
环境变量配置
| 环境变量 | 说明 | 默认值 |
|---|---|---|
ENABLE_WEB | 启用内置 Web 管理界面 | false |
API_TOKEN | 业务 Token,用于 API 调用鉴权 | 无 |
ADMIN_TOKEN | 管理 Token,用于管理 API 访问 | 无 |
GITHUB_PROXY | GitHub 代理地址,用于解决网络问题 | 无 |
MODEL_MAPPING | 模型映射配置 | 无 |
USER_AGENT | User-Agent 配置(见下方说明) | 空(透传) |
此处并非完整的配置列表,完整列表请参考项目自述文件。
数据库配置
- 默认数据库:SQLite(数据目录:
/app/data) - 可选数据库:MySQL、PostgreSQL
- 数据持久化:建议将
/app/data目录映射到宿主机
鉴权机制 (Token)
- 业务 Token:用于常规 API 调用时的身份验证。
- 管理 Token:用于访问管理接口。若未单独设置,默认复用业务 Token。
- 无鉴权模式:若两者均未设置,系统将运行在无鉴权模式下(不推荐在公网环境使用)。
网络配置建议
- 前端访问:
- 网络加速:
- Docker 镜像:若无法访问 GitHub Container Registry,可使用南京大学镜像源:
ghcr.nju.edu.cn/meowsalty/pinai:latest。 - GitHub 代理:若服务器无法直接访问 GitHub,建议配置代理地址,例如:
https://gh-proxy.com。
- Docker 镜像:若无法访问 GitHub Container Registry,可使用南京大学镜像源:
模型映射
针对部分强制要求特定模型名称的应用(如 Claude Code),系统提供了模型映射功能。
- 配置格式:
原始模型名:目标模型名,原始模型名2:目标模型名2 - 工作原理:启用后,系统会在转发请求前,自动将请求中的“原始模型名”替换为配置的“目标模型名”。
User-Agent 策略
该配置用于控制转发给上游 AI 服务时的 User-Agent 请求头。支持以下三种模式:
- 透传模式(默认):若不设置或留空,系统将直接透传客户端的 User-Agent。
- 默认模式:设置为
default时,不手动添加 User-Agent 头,使用底层 HTTP 库(fasthttp)的默认值。 - 自定义模式:设置为其他字符串时,将使用该字符串作为 User-Agent。
可通过设置 USER_AGENT 环境变量来调整此策略。
快速开始
初始化配置
- 访问界面:在浏览器中打开
http://127.0.0.1:3000。 - 连接设置:
- 点击页面顶部的“默认 API 服务器”。
- 在弹窗中配置服务器信息。
- API 密钥:输入您在环境变量中设置的 Token(优先使用
ADMIN_TOKEN)。
- 保存生效:保存配置并刷新页面。
- 添加服务:点击侧边栏的“供应商”菜单,开始添加 API 服务提供商。
API 接口调用
拼好 AI 提供以下兼容接口:
| 接口类型 | 基础路径 | 说明 |
|---|---|---|
| OpenAI | /openai | 兼容 OpenAI API 格式 |
| Anthropic | /anthropic | 兼容 Anthropic API 格式 |
管理界面详解
拼好 AI 提供了一个功能完整的 Web 管理界面,主要分为三个核心模块:
仪表盘
仪表盘提供了系统的全景视图,包含三个核心维度:
1. 实时监控
- QPS (调用频率):展示最近 1 分钟内的 API 请求速率。
- 并发连接:显示当前活跃的连接数。
2. 统计概览 (24H)
展示最近 24 小时内的关键性能指标:
- 总请求数:模型调用的累计次数。
- 请求成功率:成功响应的请求占比。
- 平均 TTFT:流式请求的平均首字时间 (Time to First Token),不包含故障转移耗时。
- Token 消耗:输入 (Prompt) 和输出 (Completion) 的 Token 统计。

3. 用量排行 (Top 5)
展示最近 24 小时内的数据排行:
- 热门模型:调用次数最多的模型。
- 活跃平台:调用次数最多的供应商平台。
- 模型消耗:Token 用量最大的模型。
- 平台消耗:Token 用量最大的平台。

供应商
供应商管理模块支持完整的增删改查 (CRUD) 操作,并集成了以下高级功能:
1. 批量导入
支持通过 CSV 格式快速导入供应商信息:
1 | [类型],[名称],[端点],[密钥] |
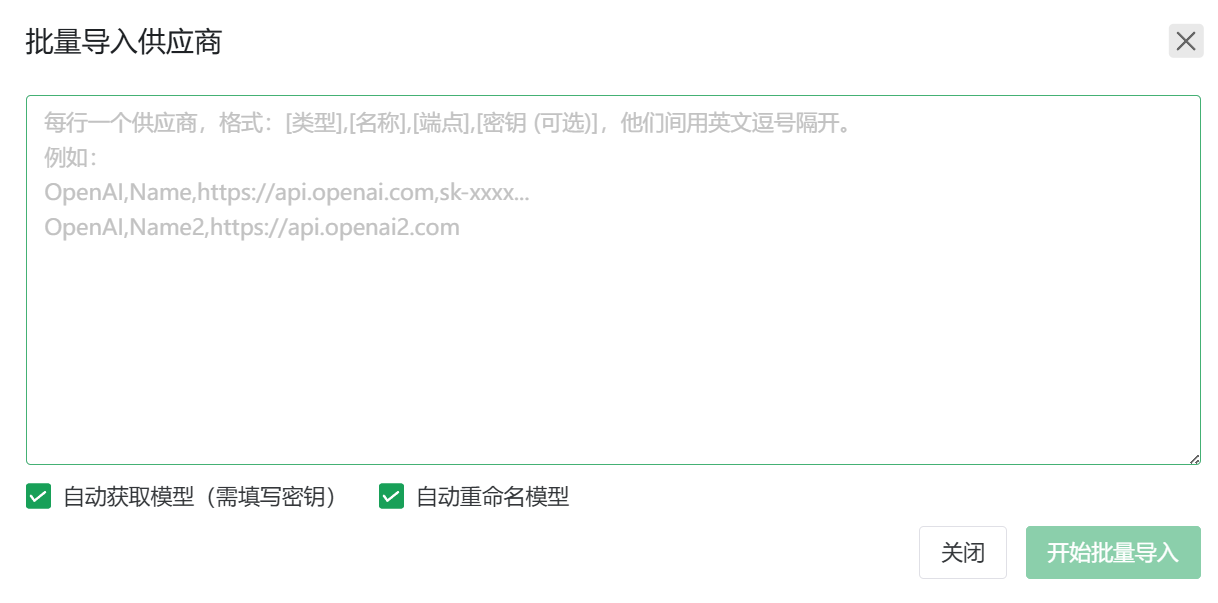
字段说明:
- 类型:支持
OpenAI、Anthropic或Gemini。 - 名称:供应商的标识名称。
- 端点:API Base URL(例如:
https://api.example.com)。 - 密钥:API Key。
提示:勾选“自动获取模型”后,系统将在导入时自动尝试拉取该供应商的模型列表。
2. 模型自动同步
在供应商编辑页,点击“获取模型”即可同步上游模型列表。
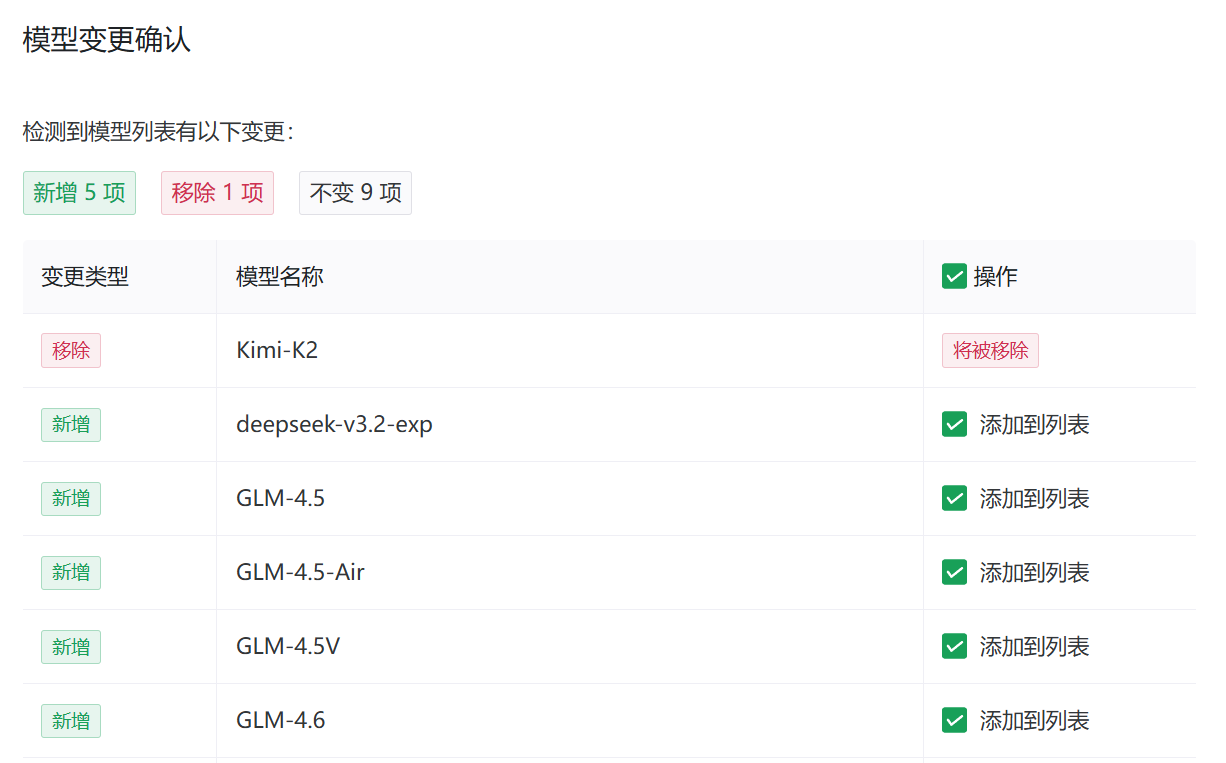
功能特性:
- 自动对比现有模型列表,展示差异。
- 支持选择性更新,避免覆盖自定义配置。
3. 模型名称重写 (Rewrite)
系统支持强大的模型名称重写引擎,包含四种处理模式:
- 插入:在指定位置插入字符。
- 替换:简单的字符串替换。
- 正则:基于正则表达式的高级替换。
- 大小写:统一转换为大写或小写。
规则执行逻辑:
- 规则链按顺序自上而下执行。
- 支持拖拽排序及单独启用/禁用。
默认预设规则:
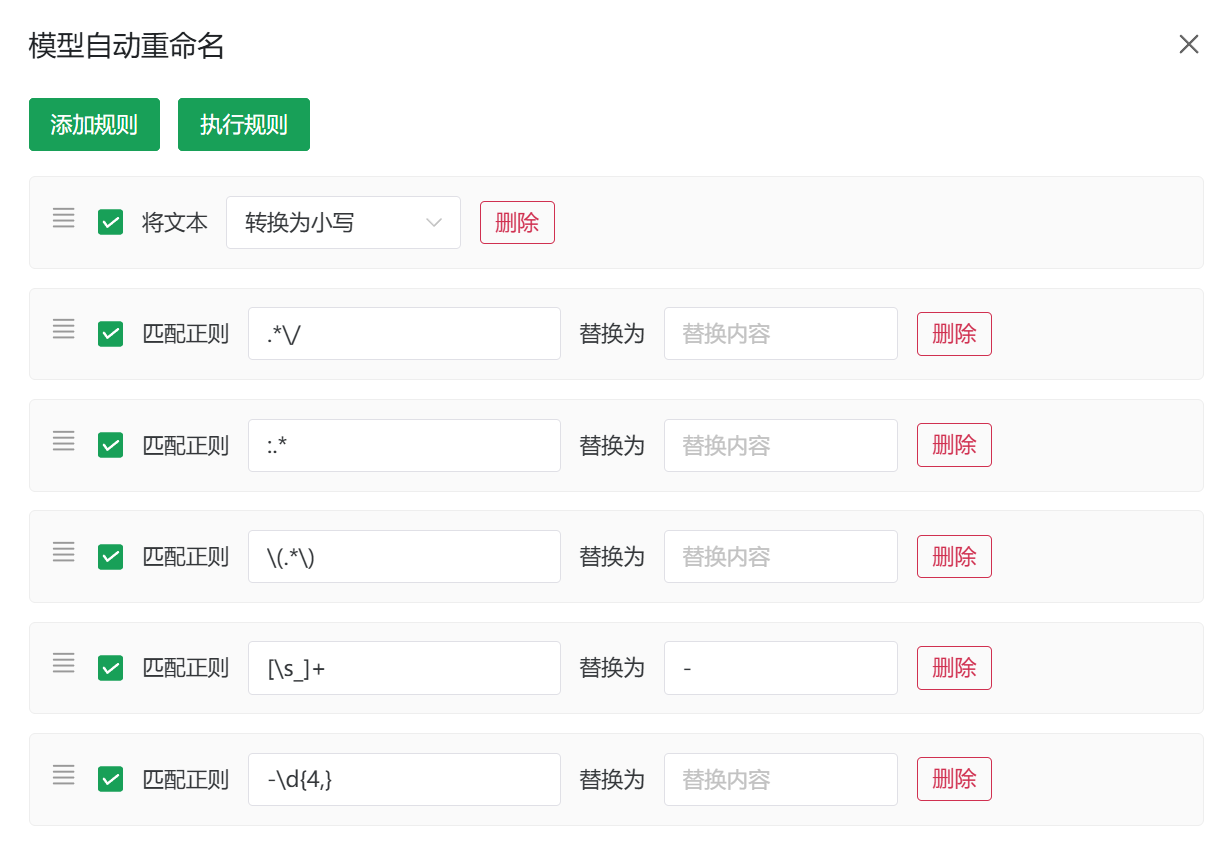
- 全转小写
- 移除分组标识
- 统一使用连字符
- 移除日期后缀
正则配置示例:
1 | // 目标:将 claude-3-7-sonnet 转换为 claude-sonnet-3.7 |
4. 批量更新
支持选中多个供应商,一键触发模型列表更新。

支持选项:
- 自动同意变更:跳过差异确认步骤。
- 自动重命名:更新后立即应用重命名规则。
请求日志
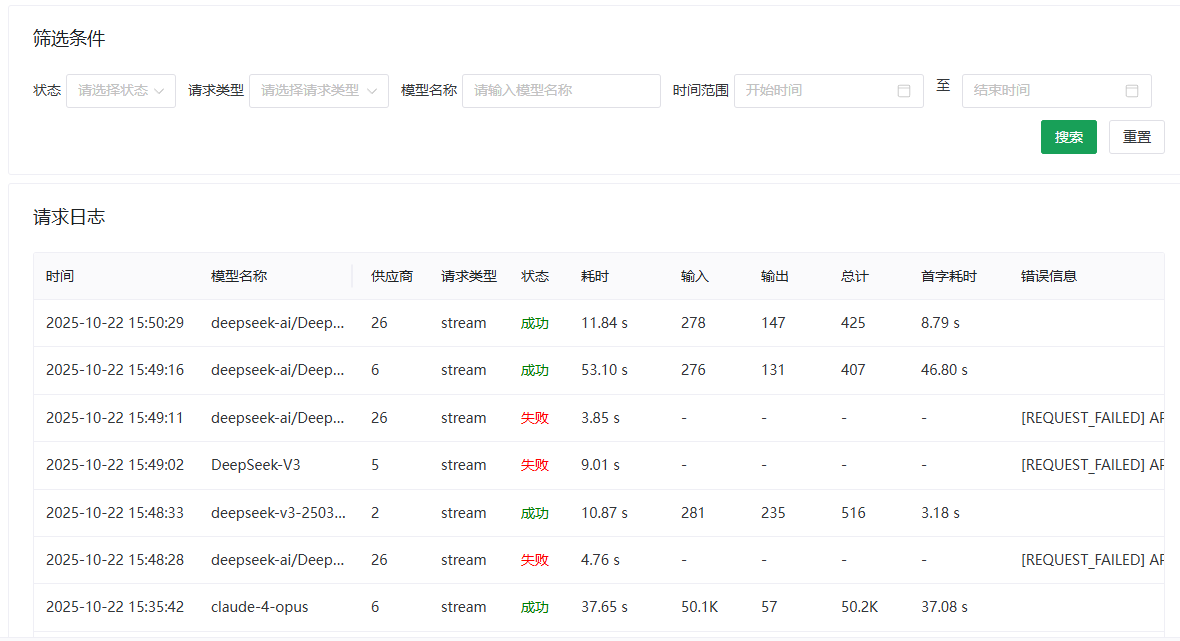
日志模块记录了详细的 API 调用链路信息:
- 时间戳:请求发起时间。
- 真实模型:实际处理请求的模型名称。
- 路由节点:实际处理请求的供应商。
- 模式:流式 / 非流式。
- 状态:HTTP 状态码及成功/失败标记。
- 总耗时:请求完整生命周期耗时。
- Token 统计:Prompt / Completion Token 消耗。
- TTFT:首字响应时间 (Time To First Token)。
- Trace:错误堆栈及详细报错信息。
尾巴
因为拼好 AI 目前其实是还没出到正式版的,基本上是一边用一边修修补补,因此功能和特性估计都不是很稳定,凑合着用吧(x
